![[forCode]](https://www.forcode.es/wp-content/uploads/2014/10/forCode_default.png)
En la entrada anterior de esta serie vimos la aritmética de punteros, la relación entre punteros y arrays y los punteros a constantes (y aprovechamos para introducir los conceptos de rvalue y lvalue).
En este post vamos a introducir la gestión manual de memoria así como el concepto de pila.
Creación de objetos y la pila
En C++ no existe el concepto de garbage collector que tienen lenguajes como Java o C#. Eso significa que cuando creamos un objeto luego debemos destruirlo cuando ya no sea necesario. Eso suena sencillo en teoría pero es mucho más complejo de lo que parece y es una de las causas de más errores en los programas codificados en C++. En capítulos posteriores de esta serie veremos una alternativa más actual a la gestión manual de memoria: los smart pointers… Pero eso será, como digo, más adelante.
En C++ podemos crear objetos en dos lugares: en la pila (stack) o en la memoria dinámica (heap a veces traducido por montículo). Crear un objeto en la pila es la forma «natural» de hacerlo y no requiere código específico. Vamos a empezar por definir una clase Beer:
class Beer {
const char* _name;
public:
inline void setName(const char* name) {
_name = name;
}
inline const char* getName() {
return _name;
}
};
Esta clase tiene un puntero a carácter (char*) para guardar el nombre de una cadena. Una de las formas «tradicionales» de C++ para guardar cadenas es usar un puntero que apunta al primer carácter de la cadena y asumir que los caracteres estarán en posiciones contiguas en la memoria. Eso nos permite usar aritmética de punteros para obtener todos los caracteres hasta llegar a un caracter marcador que indica el fin de la cadena y que es el carácter cuyo código ASCII es 0 (denotado habitualmente usando \0). Este tipo de cadenas se conocen con el nombre de cadenas ASCIIZ (la Z final hace referencia al carácter código ascii 0 usado para marcar el fin) y son una herencia de C. C++ como lenguaje incorpora mejores mecanismos que este para gestionar cadenas.
Para crear un objeto en la pila simplemente declaro una variable de este tipo:
Beer beer = Beer();
beer.setName("Punk IPA");
std::cout << "\n" << beer.getName();
Analicemos con calma lo que tenemos porque no es tan trivial.
- Por un lado tenemos el propio objeto Beer. Este objeto ha sido creado en la pila en la primera línea de código. La variable beer contiene este objeto.
- La variable _name del objeto Beer es un const char* por lo tanto apuntará a la dirección de memoria de un carácter. Insisto, por norma general cuando veas char* o const char* en C++ la idea es que sea usado como cadena ASCIIZ. El método setName recibe un const char* cuyo valor es «Punk IPA» (un literal cadena)
- El compilador de C++ trata los literales cadena como un array de caracteres cuyo tamaño es el número de caracteres del literal cadena más uno ya que el propio compilador añade el carácter \0 al final del literal. Así «Punk IPA» es un const char[9] (8 caracteres más el \0 final). Este array de caracteres se almacena en… bueno, lo veremos luego.
- En el post anterior vimos que los arrays y los punteros eran equivalentes. Por lo tanto el literal cadena «Punk IPA» que el compilador traduce a un const char[9] lo podemos pasar al método setName que recibe un const char*.
Por lo tanto este código al final termina imprimiendo «Punk IPA» por pantalla.
Empecemos ahora a ver las implicaciones de lo que hemos hecho. Imagina el siguiente código:
void setBeerName(Beer* beer) {
beer->setName("Punk IPA");
}
int _tmain(int argc, _TCHAR* argv[])
{
Beer beer = Beer();
setBeerName(&beer);
std::cout << "\n" << beer.getName();
return 0;
}
La pregunta es muy sencilla: ¿qué imprimirá por pantalla este código? A primera vista parece un mero refactoring sin importancia del código anterior. Pero… ¿hay otras implicaciones?
Bien, si has dicho que el código imprimirá Punk IPA has acertado. Pero (a no ser que conozcas algunas de las interioridades de C++) probablemente has acertado «de chiripa». La realidad es que este código imprimrá «Punk IPA» pero para entender por qué antes déjame dedicarle unas palabras a esa «pila» de la que estamos hablando.
La pila…
Hasta ahora hemos ido hablando alegramente de la pila pero ¿sabes exactamente qué es la pila? Pues la pila es una zona de memoria donde se guardan todas las variables locales de los métodos (funciones) que se han ido llamando. Se le llama pila precisamente porque está es una estructura de datos LIFO (Last In First Out) tal como una pila de platos: el último plato puesto en la pila (el que está arriba, llamado generalmente «top») es el primero que se saca de ella (a no ser que no te importe romper toda la vajilla que tu suegra te haya regalado). La pila es global y solo hay una.
Imagina un programa que empieza en una función (todos los programas empiezan por una llamada generalmente main o alguna variante tipo _tmain) que declara una variable (en la pila) llamada i1. Luego llama a otra función llamada foo() que declara en la pila otra variable i2 y foo() llama a otra función llamémosla bar() que crea otra variable en la pila llamada i3. El estado de la pila después de crear la variable i3 en bar() es el siguiente:
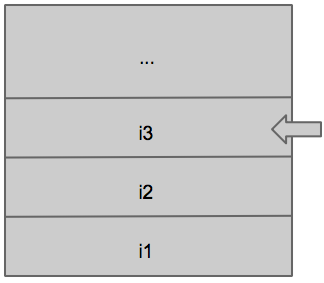
La flecha gris representa el último elemento de la pila y se conoce generalmente con el nombre de SP (Stack Pointer). Se puede ver que las 3 variables creadas por main, foo y bar están en la pila. Ahora viene lo más importante a tener en cuenta de la pila: cuando se sale de una función se eliminan los valores que dicha función haya metido en la pila. Es evidente que siempre se sale de la última función ejecutándose, así que lo que realmente ocurre es que al salir de una función el SP se mueve x bytes para «abajo» de forma que el nuevo «último elemento» de la pila es la última de las variables locales de la nueva función actual. En nuestro caso cuando salgamos de bar, el valor de i3 es eliminado de la pila y la flecha gris (el SP) pasa a apuntar a i2, indicando que i2 es el nuevo «top» de la pila.
Desplazar el SP hacia abajo (o lo que es lo mismo eliminar las variables locales de la pila al salir de una función) es lo que se conoce como «stack clean-up» y dependiendo de quien lo haga, cómo y cuando tenemos las distintas convenciones de llamada siendo las más famosas pascal, stdcall y cdecl, aunque no es necesario entrar en detalle.
Literales de cadena y la pila
Vale, ahora que ya tenemos claro como funciona la pila, revisa de nuevo el código anterior y piensa en que ocurriría si el literal de cadena «Punk IPA» se guardase en la pila. El literal de cadena es de hecho una variable (temporal y sin nombre, pero una variable) y es local al método así que teóricamente debería guardarse en la pila. Si eso fuese así, entonces el literal sería introducido en la pila en la función setNameBeer por lo que al salir de setNameBeer este literal será eliminado de la pila por lo que el puntero _name del objeto Beer apuntaría a una dirección de memoria errónea, ya que su contenido («Punk IPA») hubiese sido eliminado. Tendríamos un dangling pointer. Por suerte los literales de cadena no se guardan en la pila, pero eso es una excepción a una norma en C++. Debido a su naturaleza los literales de cadena se guardan en una zona específica y se mantienen durante toda la ejecución del programa. Pero insisto, es una excepción. Fíjate que ocurre si en lugar de un literal de cadena colocamos un array de chars declarado de forma manual:
void setBeerName(Beer* beer) {
const char name[9] = { 'P', 'u', 'n', 'k', ' ', 'I','P','A', 0 };
beer->setName( name);
std::cout << beer->getName();
}
Si ahora ejecutas de nuevo, verás que se imprime «Punk IPA» en la primera línea y una serie de carácteres aleatorios en la segunda. Eso es porque el primer cout (el que está en setBeerName) todavía tiene en la pila el array contenido en la variable local name así que entonces el puntero _name del objeto Beer apunta a una dirección de memoria donde hay contenido válido. Pero tan buen punto salimos de setBeerName el contenido de la pila es destruido, por lo que cuando se ejecuta el segundo cout (el que está en _tmain) el puntero _name apunta a datos «arbitrarios». Tienes un dangling pointer como la copa de un pino.
¿Has hecho la prueba y te imprime dos veces Punk IPA? Sí. Eso puede suceder. De hecho si ejecuto el código en release y no en debug usando Visual Studio eso es justo lo que sucede. La razón es que realmente, por rendimiento, el contenido de la pila no se elimina, tan solo se decrementa el SP, por lo que (si no se sobreescribe) el contenido de la pila sigue estando ahí. Así, si no hay ninguna otra función que cree variables locales entre el retorno de setBeerName y el cout situado en _tmain (como es nuestro caso) el puntero _name apunta a un contenido obsoleto pero todavía no eliminado y nos «parece» que todo funciona. Pero es de pura casualidad. Es por ello que para ayudar a detectar errores, en Debug el compilador sobreescribe el contenido de la pila con «datos basura» antes de decrementar el SP. En C++ la diferencia entre Debug y Release es muy importante.
La memoria dinámica
Perfecto, tenemos claro que cualquier objeto guardado en la pila es eliminado al salir de la función que lo declara. Es por ello que p. ej. no necesitamos destruir el objeto Beer creado en _tmain porque se destruye al salir de _tmain ya que está en la pila. Pero dado que los objetos almacenados en la pila solo existen mientras la función que los ha creado está ejecutándose (es decir no se ha terminado) eso los invalida para devolverlos como valores de retorno:
Beer* getDevils() {
Beer beer = Beer();
beer.setName("Marina Devil's");
return &beer;
}
int _tmain(int argc, _TCHAR* argv[])
{
Beer* pBeer = getDevils();
std::cout << pBeer->getName();
return 0;
}
Este código imprimirá de nuevo caracteres aleatorios, ya que al salir de la función getDevils() el objeto Beer que se crea en la pila es eliminado, por lo que el punteo pBeer pasa a apuntar a una dirección de memoria (de la pila) donde ya no hay el objeto esperado. Por supuesto si getDevils() devolviese Beer y no Beer* entonces todo funcionaría correctamente, pero eso porque se usaría el paso por valor por lo que en _tmain recibiríamos una copia del objeto Beer creado en getDevils. Eso para clases pequeñas es perfecto, pero para clases grandes el coste de copiar estos objetos no es asumible y por ello se usan punteros (pasar un puntero es muy rápido ya que solo hay que devolver una dirección de memoria que ocupará generalmente entre 4 y 8 bytes).
La solución pasa por, en el método getDevils(), crear el objeto no en la pila si no en la memoria dinámica (el heap) y para ello se usa el operador new:
Beer* getDevils() {
Beer* beer = new Beer();
beer->setName("Marina Devil's");
return beer;
}
El operador new devuelve ya un puntero que apunta a la zona de la memoria dinámica donde se ha creado el objeto. Ahora el objeto beer creado en getDevils() no es destruído automáticamente al salir de la función, lo qué arroja una duda: «¿quién lo elimina?». Pues la respuesta es nadie y es que ahora tenemos un memory leak. Los memory leaks son objetos creados y no eliminados por lo que se quedan ocupando memoria hasta que bueno… el programa se termina o bien el heap se queda sin memoria disponible (lo que suele ser un error fatal).
Debemos eliminar el objeto nosotros y para ello debemos usar el operador delete:
Beer* pBeer = getDevils(); std::cout << pBeer->getName(); delete pBeer;
Fíjate que el objeto lo crea un método (getDevils) y lo destruye otro (quien sea, cuando haya terminado de usar el objeto). Un aspecto importante es que llamar a delete borra el objeto pero no hace nada con el puntero. Es decir después de llamar a delete, el puntero pBeer sigue apuntando donde apuntaba salvo que ahora el objeto ya no está (pBeer se convierte en un dangling pointer). La dificultad de la gestión manual de memoria está en saber quien puede llamar a delete, ya que una vez llamado cualquier puntero que apuntaba a dicho objeto deja de ser válido. A veces no queda nada claro de quien es la responsabilidad de eliminar un objeto, ya que, como hemos visto, no puede asignarse dicha responsabilidad a quien ha creado el objeto (el método getDevils() en nuestro caso). Eso es especialmente complejo cuando tienes varios punteros que apuntan al mismo objeto en distintos métodos y saber quien es el último que deja de usar el objeto (para llamar a delete) no es trivial.
Bueno… en este post hemos introducido la pila y visto la gestión manual de memoria. En el siguiente post de la serie daremos una vuelta de tuerca más y veremos el concepto de… puntero a puntero.
Saludos!